We recently launched floating routing - a world first, Citymapper will show you how to complete journeys using floating transport.
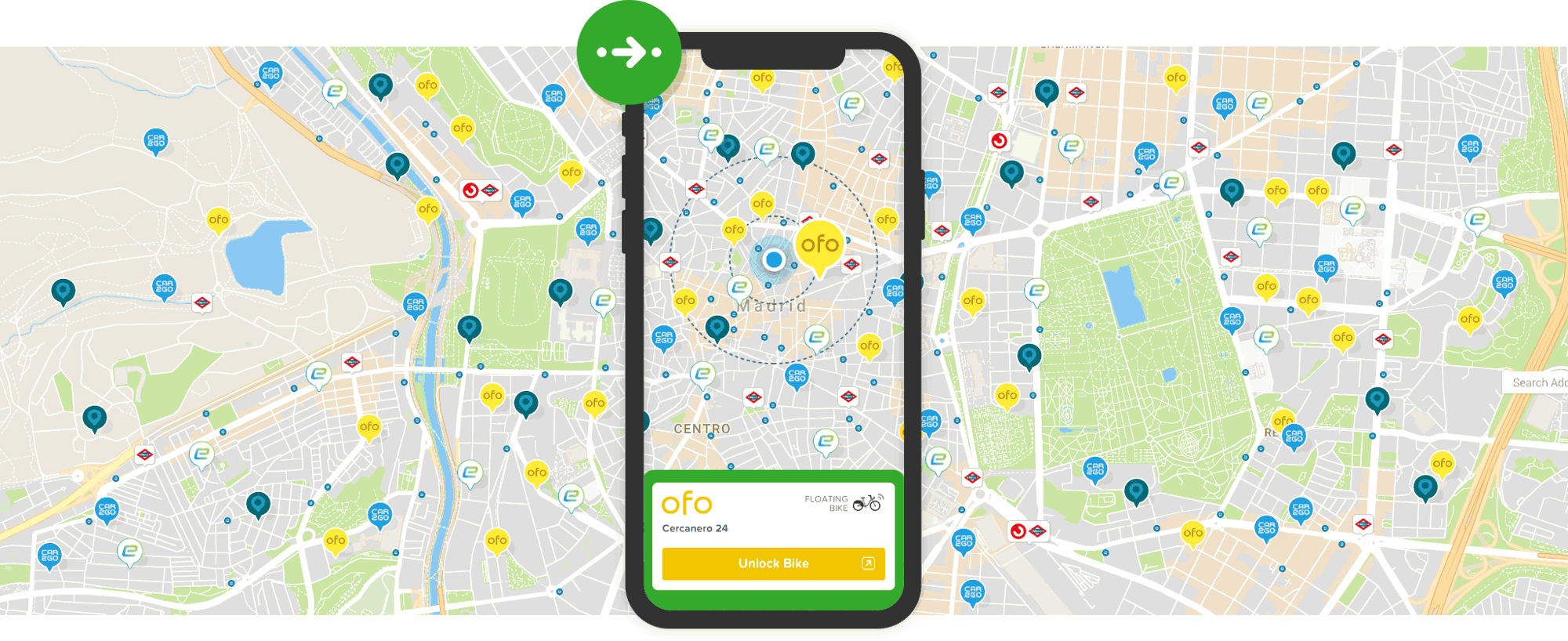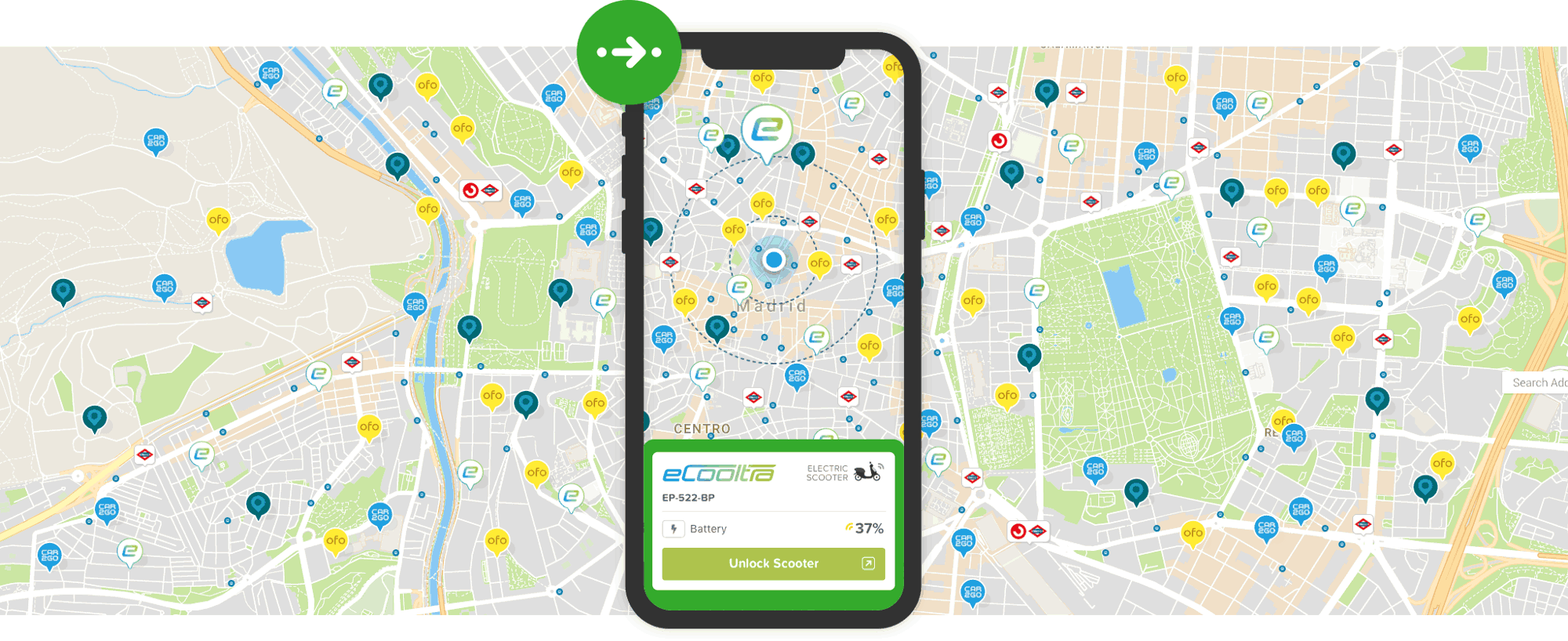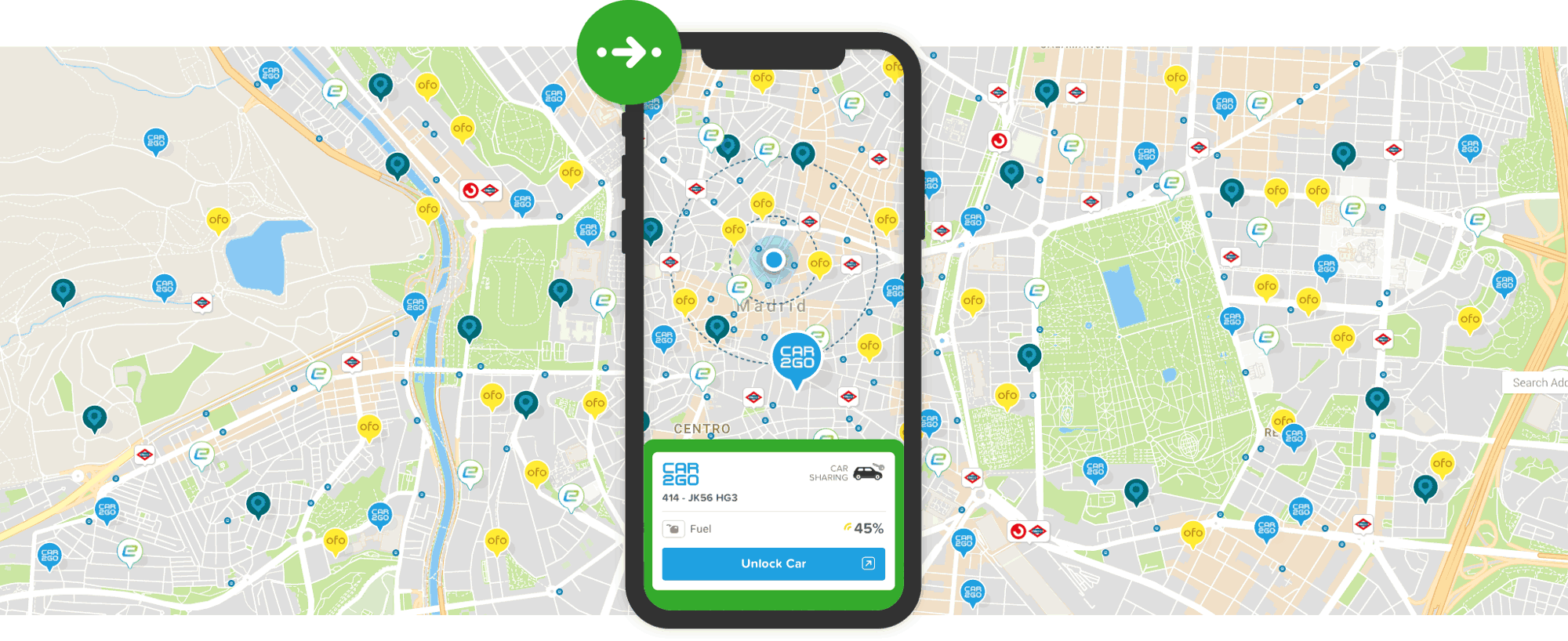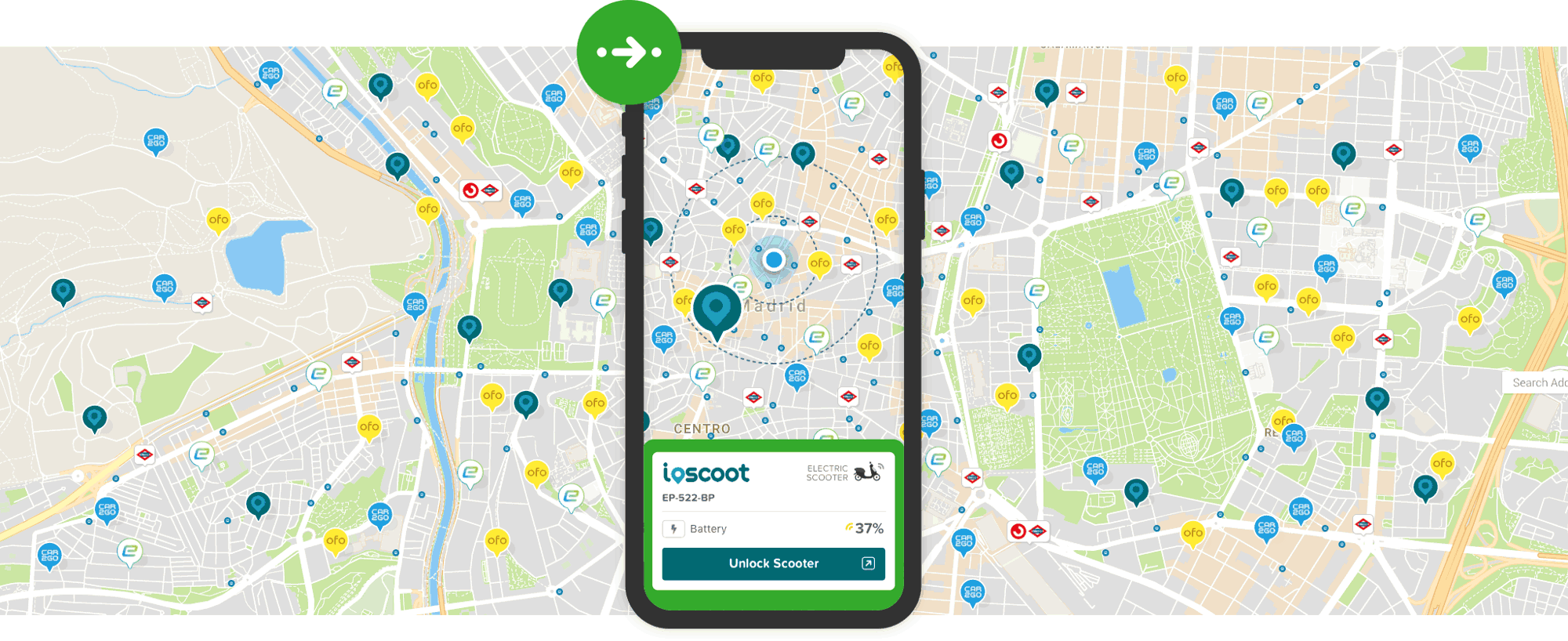
In what was no way a coincidence, our backend servers simultaneously started to run out of memory.
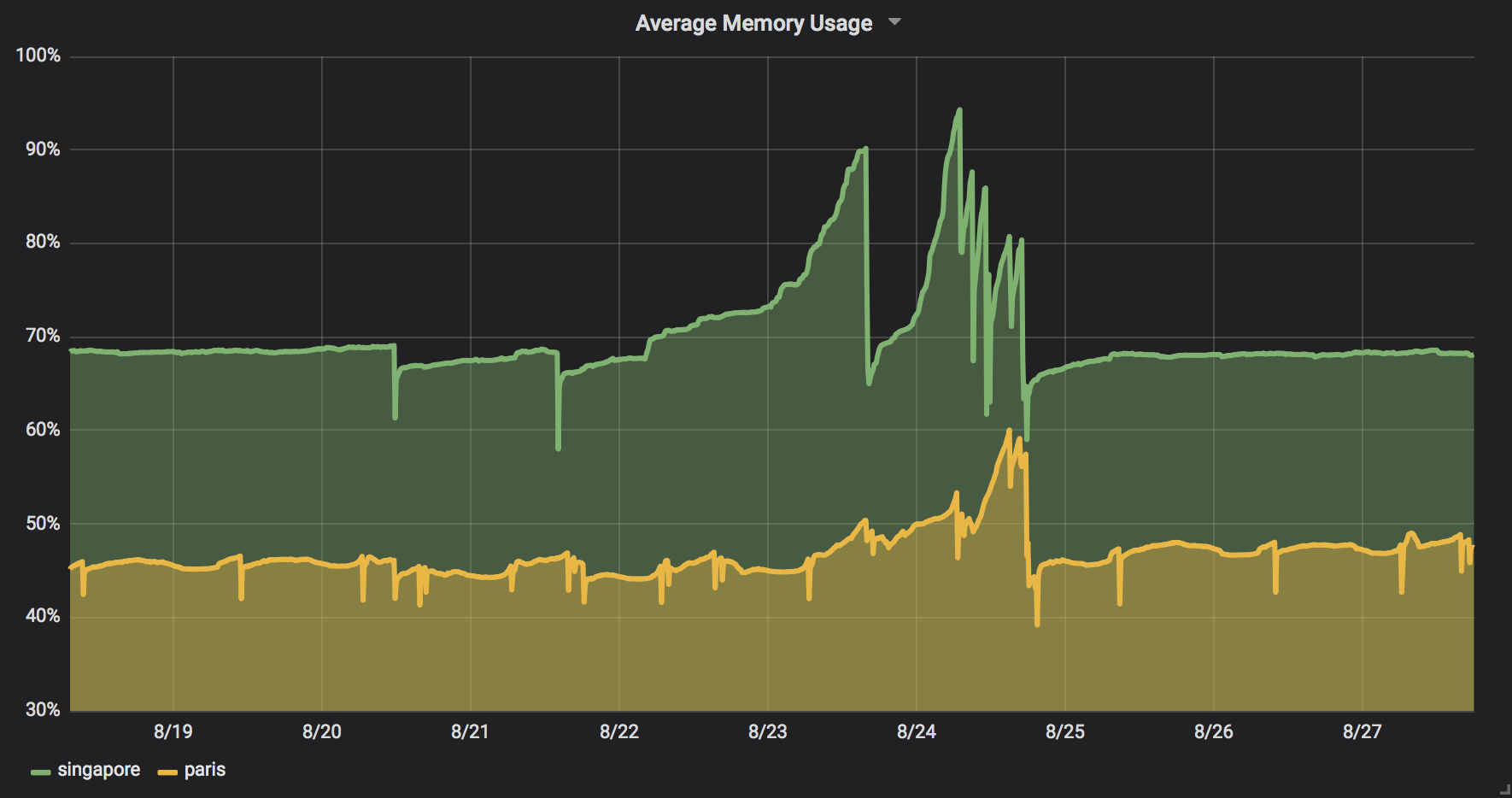
We were immediately alerted to the issue when a server crashed on Friday morning. With a bit of skill and a bit of luck, we had shipped a fix to production the same day.
Street Knowledge
A memory leak is a bug where the amount of memory that your application is using grows indefinitely. This is a great way for your server to eventually crash.
Looking at our dashboard, we noted that our available memory Singapore was depleting much faster than in Paris.
As engineers at Citymapper, we have excellent intuition about what makes cities unique. Specifically, we knew that floating vehicle hire is a relatively new concept in Paris, in contrast to Singapore where many schemes are well established.
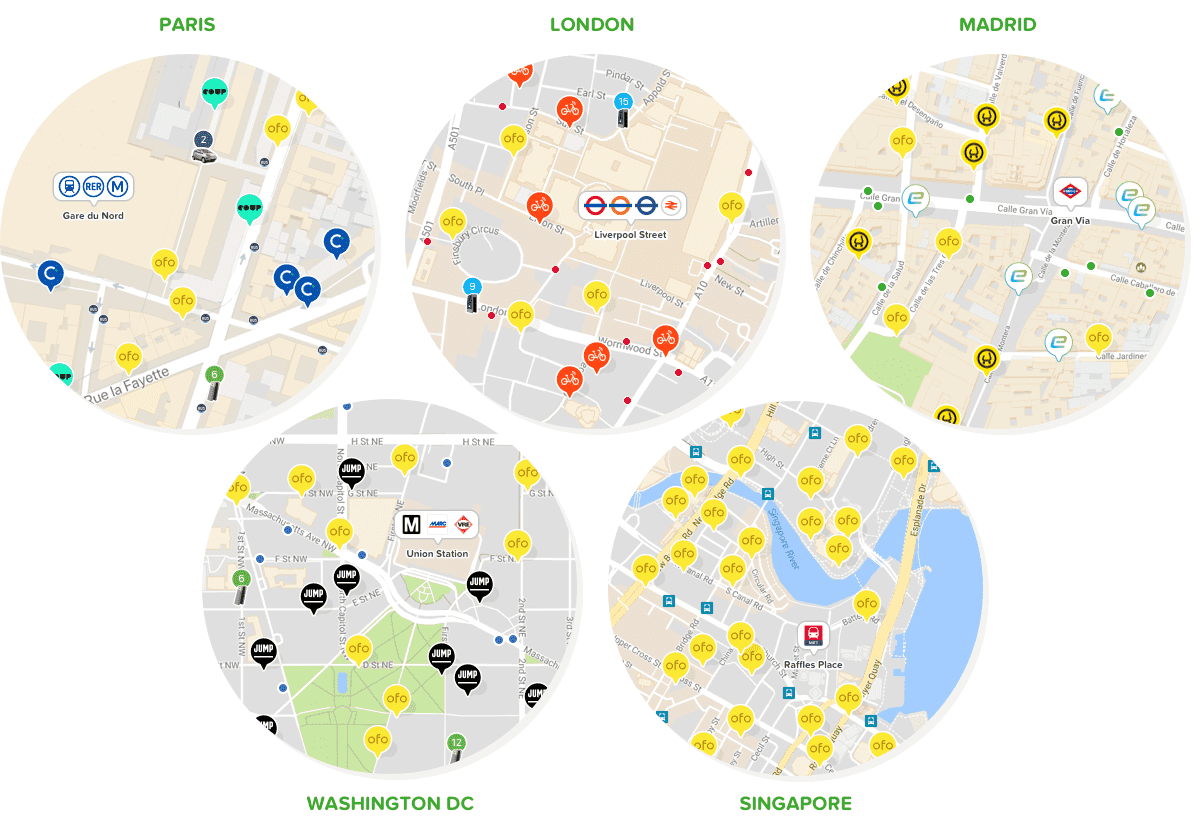
We speculated that the size and speed of the leak was correlated with the number of floating vehicles that a city had.
Could it be that our servers were leaking the vehicles themselves?
Server Knowledge
In theory, a web server should:
- Initialise any shared state
- Serve a request, allocating any memory needed
- Free any allocated memory
What we really wanted was to understand why step 3) was not happening. Ideally, we could replay some production traffic from Singapore on our development machines. We could then attach some instrumentation that would show us which objects were left over once a request had finished.
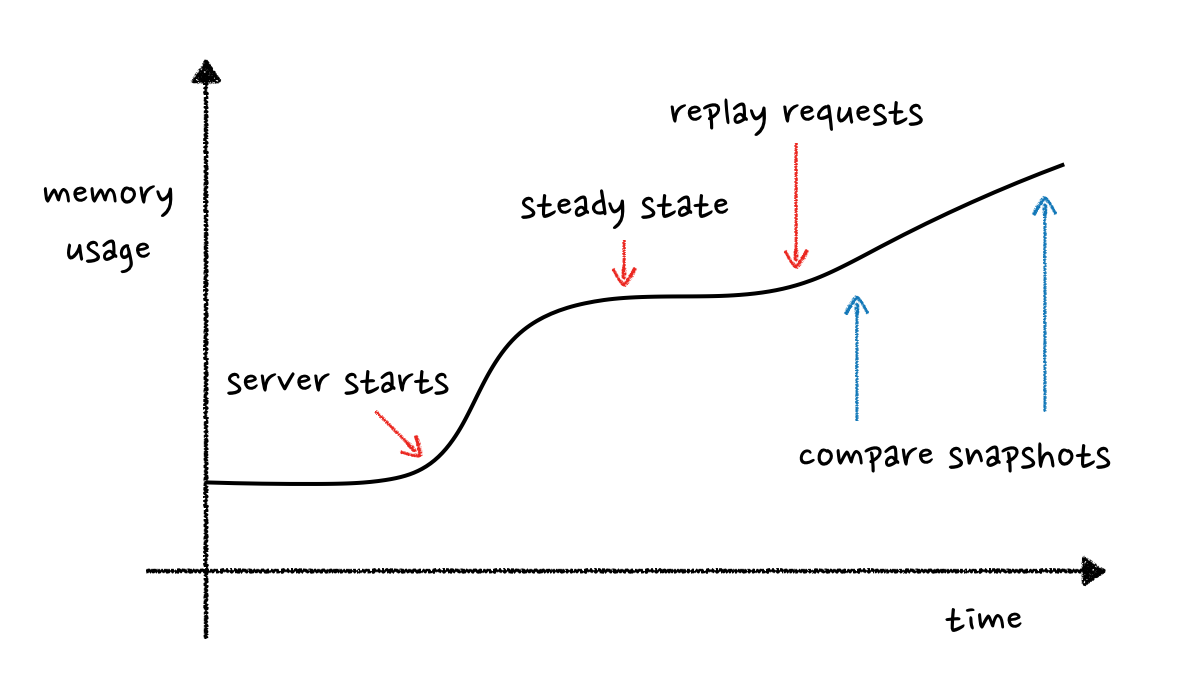
If we could take a snapshot of all of our Python objects in memory at a specific point in time, we might stand a chance of confirming which objects were leaking by comparing two snapshots.
Guppy
Our API servers are written in Python. We needed a language specific tool that could hook into the CPython virtual machine and snapshot objects in memory.
We found that guppy is an excellent tool for comparing heap snapshots in Python.
import guppy
hp = guppy.hpy()
before_heap = hp.heap()
refresh_floating_vehicles() # critical section
leftover = hp.heap() - before_heap
print(leftover.byrcs) # shows which objects remain on the heap
In this case, the code that was responsible for refreshing floating vehicles seemed to be just fine. This meant that the leak was somewhere else in our codebase. We needed to dial things up a notch.
Calling Doctor Thread
Instead of bisecting our code, we realized that we could use guppy as the basis of a diagnostic tool which reports on the size of the heap over time.
Here it is in all of it's glory:
import gc
import logging
import threading
import guppy
class DoctorThread(threading.Thread):
def __init__(self):
Thread.__init__(self)
self.daemon = True
self.hp = guppy.hpy()
def run(self):
time.sleep(30) # sleep a bit to allow any caches to warm up
logging.info("Doctor Thread started - taking heap snapshot")
before_heap = self.hp.heap()
while True:
gc.collect() # force GC before a heap snapshot
leftover = self.hp.heap() - before_heap
logging.info(leftover.byrcs) # prints any leftover objects to the terminal
time.sleep(10)
DoctorThread().start()
We dropped Doctor Thread right at the end of our API server launch code and replayed our sample of requests. Interestingly, many of them did not trigger a leak.
By this point, we had greatly simplified the code that refreshed the floating vehicles cache. Instead of refreshing the bikes from our upstream data sources, we generated 10,000 fake bikes and dropped them around Singapore.
After a bit of luck, we found that one request that had triggered an exception had managed to leak our 10,000 bikes into memory. A second request then also triggered an exception, leaking 10,000 more.
Memory usage: 577.29024mb
Partition of a set of 233109 objects. Total size = 39100560 bytes.
Index Count % Size % Cumulative % Referrers by Kind
1 20000 17 3199680 8 30821312 79 FloatingVehicle
Doctor Thread had shown us that the problem was not directly related to floating vehicles, but instead was related to exception handling.
Solving the Problem
Several essential factors enabled us to solve this problem relatively quickly as a team:
- We were able to replay samples of traffic on our local development machines
- Our sample of requests was large enough to contain a handful of problematic requests that triggered the leak
We now just needed to bisect our code to find out why the objects were leaking.
This was pretty straightforward, as we had acquired more pieces of the puzzle. We knew that memory was leaked when our routing pipeline threw an exception, and that normal requests were not affected.
We ended up shipping two fixes: We fixed the exception that caused the leak, and we also fixed the code that was prone to leaks if an exception was raised.
The bug that made our code prone to leaks was quite subtle. Before:
from multiprocessing.dummy import Pool
pool = Pool()
results = pool.imap(route, iterable)
results = [result for result in results]
pool.close()
return results
And after:
from multiprocessing.dummy import Pool
pool = Pool()
results = pool.imap(route, iterable)
# iterating over results can raise an exception. ensure we free resources
pool.close()
results = [result for result in results]
return results
Before we applied our fixes, our leaking vehicles were able to ratchet up a vast amount of memory:
python: 1.2Gb
and After:
python: 324.3mb
In the subsequent weeks since launch, we've launched a plethora of integrations with floating vehicle providers across more than 20 cities around the world. How many can you find?
